Thought an art thread for AI generated images would be fun. There is a few different AIs now and they are really good.
/cyb/ - Cyberpunk Fiction and Fact
Cyberpunk is the idea that technology will condemn us to a future of totalitarian nightmares here you can discuss recent events and how technology has been used to facilitate greater control by the elites, or works of fiction
466 replies | 449 files | 74 UUIDs | Page 5

366 replies and 321 files omitted.
Anonymous
No.2183
>>2182
>It makes sense you don't always get the same results, even when all things are equal.
Running same seed and prompt I get same image every time. Also running others prompt and seeds (I seen people post) I get same image they get when using the same model they used.
>It makes sense you don't always get the same results, even when all things are equal.
Running same seed and prompt I get same image every time. Also running others prompt and seeds (I seen people post) I get same image they get when using the same model they used.
Anonymous
No.2184
>>2182
I don't think the AI is updating its own model with data from the pictures it generates.
I hope it isn't. I don't want my AI to give itself dementia by using its garbled output as new input.
By now its garbled output probably outnumbers the number of images it was trained on.
I don't think the AI is updating its own model with data from the pictures it generates.
I hope it isn't. I don't want my AI to give itself dementia by using its garbled output as new input.
By now its garbled output probably outnumbers the number of images it was trained on.
Anonymous
No.2190
1667953434.mp4 (4.9 MB, Resolution:576x1024 Length:00:00:41, video_2022-11-07_12-36-29.mp4) [play once] [loop]
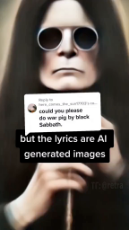
Anonymous
No.2193
Does anyone have any good images? I tried doing a cursory search on ponerpics and the first few pages were horrid dogshit.




The era of abstract merchants has reached a new golden age.
Merchants are being produced faster than the ADL could ever hope to flag them.
Merchants are being produced faster than the ADL could ever hope to flag them.
Anonymous
No.2236

Anonymous
No.2237
>>2235
Idk. I got them from Discord.
If you find out any methods, do share. I want to mass produce merchants.
Idk. I got them from Discord.
If you find out any methods, do share. I want to mass produce merchants.



Anonymous
No.2245
1668994325_1.png (722.5 KB, 1280x768, 00036-1416231330-green_eyes_s.png)

1668994325_2.png (281.3 KB, 640x384, 00033-1191004003-green_eyes_s.png)

Anonymous
No.2246
1668994653_1.png (1.1 MB, 1280x768, 00050-4283156501-watercolor.png)

1668994653_2.png (334.4 KB, 512x512, 00008-3025926800-safe_hioshir.png)

1668994653_3.png (319.5 KB, 512x512, 00019-2923236971-t-hoodie_AND_.png)

1668994653_4.png (289.2 KB, 512x512, 00002-3251689543-by_lumineko_A.png)



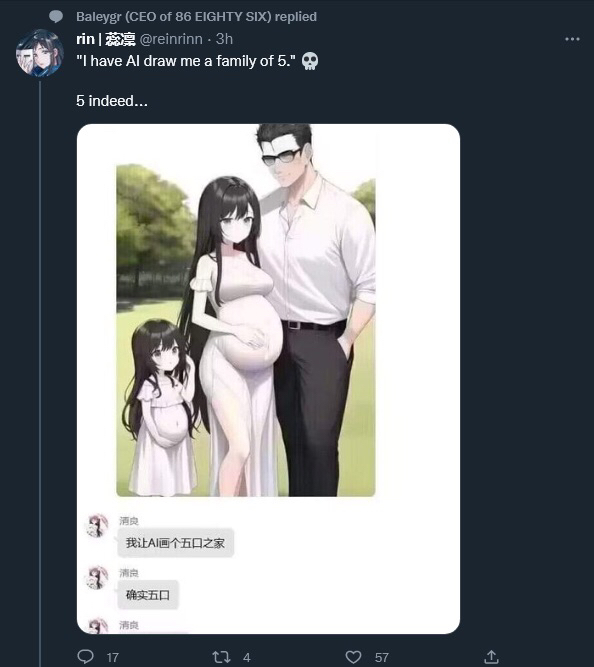
Pixiv has lost its collective mind recently (more than before).
It's impossible to use the site without being recommended pics of [i]pregnant toddlers!
It's impossible to use the site without being recommended pics of [i]pregnant toddlers!


Anonymous
No.2258
1669184042.png (11.3 MB, 3072x2560, Twilight Sparkle supposedly.png)

I got the new Everything V3 model.
It seems more varied than the previous smaller Waifu model I was using.
But it also loves to wash out the colours of anything I make with it. So I often have to saturate this desaturated art output until it looks right.
It seems more varied than the previous smaller Waifu model I was using.
But it also loves to wash out the colours of anything I make with it. So I often have to saturate this desaturated art output until it looks right.

"Twilight Sparkle"
>>2273
Nice. Not knowing prompt but adding "(unicorn)" to prompt and "(text), devil" to negative prompt might fix some of the devil horns and and text. Love how AI art is evolving with better and better models.
Nice. Not knowing prompt but adding "(unicorn)" to prompt and "(text), devil" to negative prompt might fix some of the devil horns and and text. Love how AI art is evolving with better and better models.

Anonymous
No.2276
>>2274
Speaking of AI evolution how do I update my installation of Stable Diffusion? I heard the new version has no limit on text input and is better at drawing hands.
Speaking of AI evolution how do I update my installation of Stable Diffusion? I heard the new version has no limit on text input and is better at drawing hands.
Anonymous
No.2278
>>2277
The way I do it is that I used git to get the initial code and run an git update in the bat file used to start SD.
So initially do an
>git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
Then in bat file I do
>...
>set COMMANDLINE_ARGS=--ckpt pony_sfw_80k_safe_and_suggestive_500rating_plus-pruned.ckpt --lowvram --opt-split-attention
>
>cd stable-diffusion-webui
>git pull
>call webui.bat
>cd ..
The way I do it is that I used git to get the initial code and run an git update in the bat file used to start SD.
So initially do an
>git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
Then in bat file I do
>...
>set COMMANDLINE_ARGS=--ckpt pony_sfw_80k_safe_and_suggestive_500rating_plus-pruned.ckpt --lowvram --opt-split-attention
>
>cd stable-diffusion-webui
>git pull
>call webui.bat
>cd ..
Wtf is he doing to edit the AI generated art and get new ones like that? https://m.youtube.com/watch?v=aFnGO74KsF0
>>2281
I assumed he did, but looked at description and he is using the Krita plugin for Stable Diffusion that runs an img2img with prompt. It can take basic input and you have to tell it what it should draw and weight how much it should resemble the input image. I am not fully sure how the weights should be but I think the Krita plugin is fairly easy to use.
First get Krita https://krita.org/
Then install the Krita plugin https://github.com/sddebz/stable-diffusion-krita-plugin
You can do the same in Stable Diffusion webui directly by going to the img2img tab.
I assumed he did, but looked at description and he is using the Krita plugin for Stable Diffusion that runs an img2img with prompt. It can take basic input and you have to tell it what it should draw and weight how much it should resemble the input image. I am not fully sure how the weights should be but I think the Krita plugin is fairly easy to use.
First get Krita https://krita.org/
Then install the Krita plugin https://github.com/sddebz/stable-diffusion-krita-plugin
You can do the same in Stable Diffusion webui directly by going to the img2img tab.
>>2283
Have you tried using that setting where your generator makes the image tiny and then scales it up?
Have you tried using that setting where your generator makes the image tiny and then scales it up?
>>2287
I have not tried upscaling or any of the fancy options as the biggest I can generate is 512x512 and even that is pushing my card to the limits. And it takes a couple of minutes to generate an image. So experimenting with settings and what it does is an exercise in patience and remembering what I did half an hour ago and if my changes actually had an impact.
I have not tried upscaling or any of the fancy options as the biggest I can generate is 512x512 and even that is pushing my card to the limits. And it takes a couple of minutes to generate an image. So experimenting with settings and what it does is an exercise in patience and remembering what I did half an hour ago and if my changes actually had an impact.
>>2288
Damn, that sucks. Back when I had to make do with a piece of shit laptop that would take multiple minutes to boot up and do basic tasks like open the file explorer or open a webpage, I ran Fallout New Vegas at barely 10 frames a second even with the lowest graphics settings and as few mods as possible. The game was borderline unplayable especially when combat started so I had to rely on companions basically doing all combat for me. The lag didn't fuck their attacks up as much. Even the fucking word processor lagged with that thing. A word processor!
Damn, that sucks. Back when I had to make do with a piece of shit laptop that would take multiple minutes to boot up and do basic tasks like open the file explorer or open a webpage, I ran Fallout New Vegas at barely 10 frames a second even with the lowest graphics settings and as few mods as possible. The game was borderline unplayable especially when combat started so I had to rely on companions basically doing all combat for me. The lag didn't fuck their attacks up as much. Even the fucking word processor lagged with that thing. A word processor!
Does anyone actually believe GPU prices are dropping down anytime soon?
>>2288
Specs?
>>2291
Lmao
My trashtop struggles to run Halo 2 on anything but low settings.
Android-x86 is game-changing tho. if your phone is old and shitty like mine.
I couldn't have possibly run the PC version of Honkai on that thing.
>>2288
Specs?
>>2291
Lmao
My trashtop struggles to run Halo 2 on anything but low settings.
Android-x86 is game-changing tho. if your phone is old and shitty like mine.
I couldn't have possibly run the PC version of Honkai on that thing.
>>2292
>Does anyone actually believe GPU prices are dropping down anytime soon?
There was talk that GPU prices could drop when Etherium did their change and no longer required top end GPU to mine coins (or something like that). But I assume the Manufacturers/Shops have gotten used to getting paid top dollars so sadly it might take a good while before it drops.
>Specs?
My GPU is an GTX 1060 3GB so it is on the low end to be able to run it at all.
>Does anyone actually believe GPU prices are dropping down anytime soon?
There was talk that GPU prices could drop when Etherium did their change and no longer required top end GPU to mine coins (or something like that). But I assume the Manufacturers/Shops have gotten used to getting paid top dollars so sadly it might take a good while before it drops.
>Specs?
My GPU is an GTX 1060 3GB so it is on the low end to be able to run it at all.
1669930434.jpg (61.4 KB, 500x500, artworks-tqvum3VtN9KrP2rh-5O9Fyw-t500x500.jpg)

>>2293
>But I assume the Manufacturers/Shops have gotten used to getting paid top dollars
I guess so. I remember some Anons warning about this before.
>GTX 1060 3GB
>Low-end
Welp, I guess I shouldn't even bother.
>But I assume the Manufacturers/Shops have gotten used to getting paid top dollars
I guess so. I remember some Anons warning about this before.
>GTX 1060 3GB
>Low-end
Welp, I guess I shouldn't even bother.
Anonymous
No.2295
>>2294
>Welp, I guess I shouldn't even bother.
I think minimum recommended is 4GB card and 3GB is lowest that they had been able to run it on. Still the AI is able to run on consumer grade GPU compared to others that need 40GB+ cards to run so it is much better than what it could have been. But been a while since I read the FAQ and could be they have managed to lower the spec needed (looks like 2GB vram is lowest now) People have been able to run it on CPU only but significantly slower but it is possibilities.
>Nvidia guide: https://rentry.org/voldy
>CPU guide: https://rentry.org/cputard
>AMD guide: https://rentry.org/sdamd
(think this is still the relevant guides)
>Welp, I guess I shouldn't even bother.
I think minimum recommended is 4GB card and 3GB is lowest that they had been able to run it on. Still the AI is able to run on consumer grade GPU compared to others that need 40GB+ cards to run so it is much better than what it could have been. But been a while since I read the FAQ and could be they have managed to lower the spec needed (looks like 2GB vram is lowest now) People have been able to run it on CPU only but significantly slower but it is possibilities.
>Nvidia guide: https://rentry.org/voldy
>CPU guide: https://rentry.org/cputard
>AMD guide: https://rentry.org/sdamd
(think this is still the relevant guides)
Can my hp laptop run Crysis Stable Diffusion?
Asking for a poorfag fren that might want to generate mares.
Asking for a poorfag fren that might want to generate mares.
Anonymous
No.2297
>>2296
I think if you run the CPU version it could work. Not sure though as I haven't tried the CPU one, but it might be worth checking out. If it has an Nvidia GPU with 2GB or more vram it should run according to the guide without problem.
I think if you run the CPU version it could work. Not sure though as I haven't tried the CPU one, but it might be worth checking out. If it has an Nvidia GPU with 2GB or more vram it should run according to the guide without problem.
Isn't there a command you can add to the .bat file to make it generate images slower while using less memory at once?
Anonymous
No.2299
>>2298
Yes, the "--lowvram --opt-split-attention" in the COMMANDLINE_ARGS is the command line args for lowram systems. The "--ckpt " is to select what model it uses (the pony model in this example)
>set COMMANDLINE_ARGS=--ckpt pony_sfw_80k_safe_and_suggestive_500rating_plus-pruned.ckpt --lowvram --opt-split-attention
Yes, the "--lowvram --opt-split-attention" in the COMMANDLINE_ARGS is the command line args for lowram systems. The "--ckpt " is to select what model it uses (the pony model in this example)
>set COMMANDLINE_ARGS=--ckpt pony_sfw_80k_safe_and_suggestive_500rating_plus-pruned.ckpt --lowvram --opt-split-attention
Wait do you mark a word or phrase with (((these))) or !!!these!!! to increase or decrease the importance the AI gives to those words in the request?
Anonymous
No.2301
>>2300
Yes you have a few weighting and other tricks to do in prompt. Cant remember them all or find the guide that had it all listed but I guess it is in here somewhere https://rentry.org/sdgoldmine
(((increased importance))) - the more paratheses the more importance it should be given
Yes you have a few weighting and other tricks to do in prompt. Cant remember them all or find the guide that had it all listed but I guess it is in here somewhere https://rentry.org/sdgoldmine
(((increased importance))) - the more paratheses the more importance it should be given





Anonymous
No.2303






























Anonymous
No.2309




Anonymous
No.2311
>>2307
>pic 3
The AI reinterpreted two hoes into one waifu, but one of the hoes is fat enough to be two women.
>pic 3
The AI reinterpreted two hoes into one waifu, but one of the hoes is fat enough to be two women.
Anonymous
No.2312
>>2302
Love the AI renderings. Looking forward to getting "colorized" videos in AI rendering. So much good too look forward to.
Love the AI renderings. Looking forward to getting "colorized" videos in AI rendering. So much good too look forward to.
Anonymous
No.2313
Has anyone by the way run any of the CWC comics through any of the AI's yet?







>>2320
There is an NSFW model but can't find link to it . I assume that is the one being used
...Found the link
>https://desuarchive.org/mlp/thread/39110334/#39114433
>>NSFW Pony Model Weights.
>>https://drive.google.com/drive/folders/14JyQE36wYABH-0TSV_HBEsBJ3r8ZITrS?usp=sharing
There is an NSFW model but can't find link to it . I assume that is the one being used
...Found the link
>https://desuarchive.org/mlp/thread/39110334/#39114433
>>NSFW Pony Model Weights.
>>https://drive.google.com/drive/folders/14JyQE36wYABH-0TSV_HBEsBJ3r8ZITrS?usp=sharing

why
Just updated my Stable Diffusion install, I see new buttons and features but the limit on prompts is still there.
How do I get rid of that text limit?
How do I get rid of that text limit?
>>2327
There's a limit on the number of prompts I can give the AI at once. It's around 75 words. How do I break this limit on input text?
There's a limit on the number of prompts I can give the AI at once. It's around 75 words. How do I break this limit on input text?
>>2329
Not sure, but have you tested if the limit is on number of keywords individual words or if it is on prompt sections.
Like:
>word1, word2, word3, ...
>full sentence 1, full sentence 2, ....
...
>pony, flower, lake
>pony standing in field by a lake surrounded by flowers, stars, moon, (unicorn), by Peter Elson
(I have not run these examples so I have no idea what they will produce)
Only limit I can see is on full input, but I think this is a limit in Stable Diffusion that the webui can't circumvent. But could be that there is a limit on the number of "sections" i.e. keywords, keysentences.
Not sure, but have you tested if the limit is on number of keywords individual words or if it is on prompt sections.
Like:
>word1, word2, word3, ...
>full sentence 1, full sentence 2, ....
...
>pony, flower, lake
>pony standing in field by a lake surrounded by flowers, stars, moon, (unicorn), by Peter Elson
(I have not run these examples so I have no idea what they will produce)
Only limit I can see is on full input, but I think this is a limit in Stable Diffusion that the webui can't circumvent. But could be that there is a limit on the number of "sections" i.e. keywords, keysentences.
Anonymous
No.2331




>request man in blue jacket with white flames
Wow, whoever made this AI model loves men.
Wow, whoever made this AI model loves men.
Anonymous
No.2332
>>2330
Also I updated my Stable Diffusion installation after wiping my PC. Now the text limit gets slightly higher whenever I go over the limit. Seems to be missing key words now and then, unless I'm using the wrong terms for some things like pony_ears.
Also I updated my Stable Diffusion installation after wiping my PC. Now the text limit gets slightly higher whenever I go over the limit. Seems to be missing key words now and then, unless I'm using the wrong terms for some things like pony_ears.





Holy mother of God.
Anonymous
No.2335
>>2334
Does putting Text in the negative prompt get rid of that watermark?
What about mixing the model with other models?
Does putting Text in the negative prompt get rid of that watermark?
What about mixing the model with other models?
Anonymous
No.2336
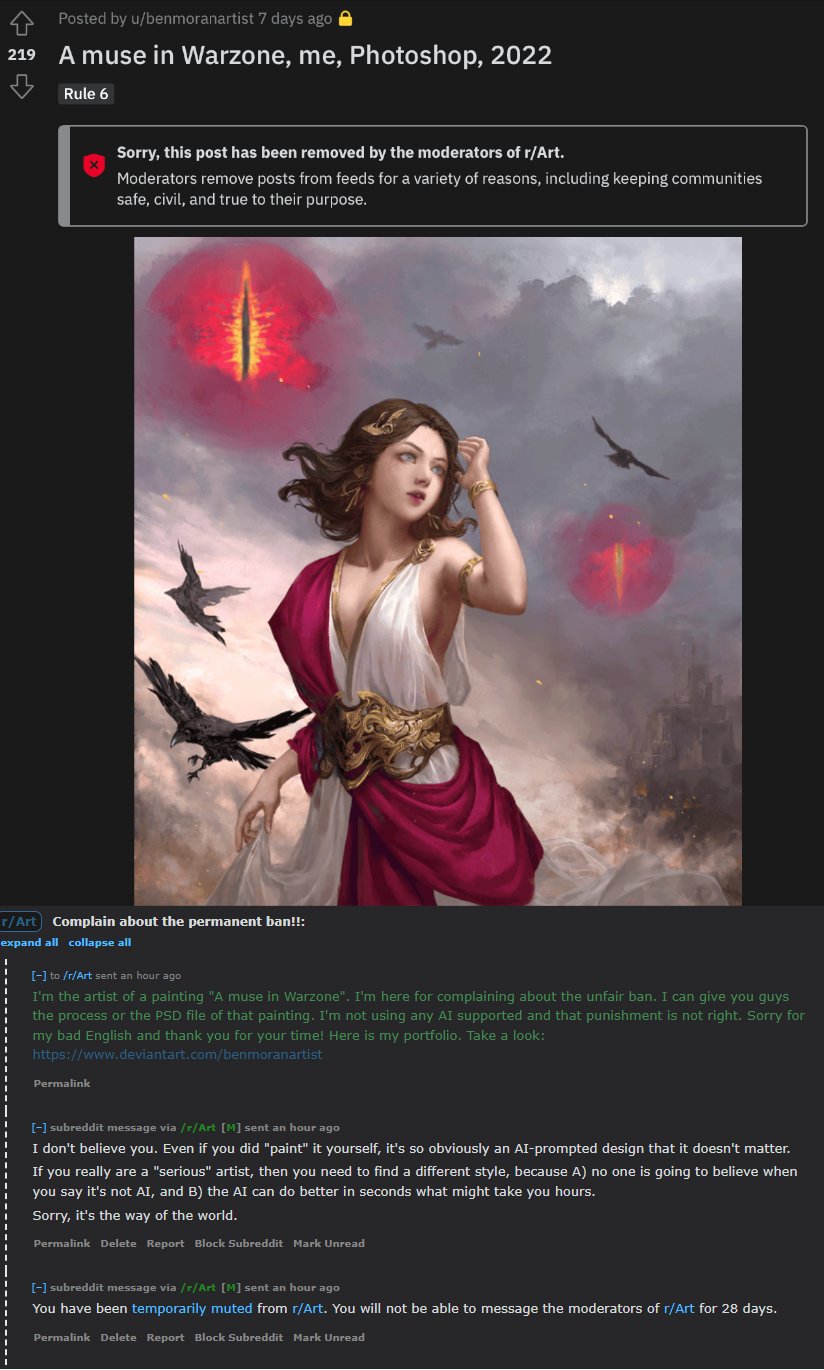

Art Subreddit Bans Guy Because His Work “Looks Like It was AI-Generated”
https://nichegamer.com/art-subreddit-bans-artist-style-ai/
https://nichegamer.com/art-subreddit-bans-artist-style-ai/
Anonymous
No.2337
Who are your favourite artists to use for art generation?




>type "horse vagina" over and over
>get this
why
>get this
why




>>2342
I thought combining AI models would make it better at producing horse pussy, not worse. What the hell is this?
I thought combining AI models would make it better at producing horse pussy, not worse. What the hell is this?
Anonymous
No.2345
>>2344
When I wrote
>blonde
no blonde hair
when I wrote (((((blonde))))) to emphasize the tag above all others I got that weird yellow pic.
When I wrote
>blonde
no blonde hair
when I wrote (((((blonde))))) to emphasize the tag above all others I got that weird yellow pic.








Rainbow Dash
I'm bored now. The art is coming out crappy. I don't think I'll do the rest of the mane six.
I'm bored now. The art is coming out crappy. I don't think I'll do the rest of the mane six.





>>2348
I don't remember if I combined those with the other models or not but I'm sure Everything V3 and an anime waifu model are in there.
The mixed model can't make good porn.
I don't remember if I combined those with the other models or not but I'm sure Everything V3 and an anime waifu model are in there.
The mixed model can't make good porn.


>>2349
Just wondered as the rendering looked a bit like the ones I got when I tried to generate MLP using Waifu model.
>pic 1 Waifu Model (v1.2)
>pic 2 Pony Model
>twilight_sparkle, mlp, seductive
>Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3967284458, Size: 512x512
>Not the best seed I guess
Just wondered as the rendering looked a bit like the ones I got when I tried to generate MLP using Waifu model.
>pic 1 Waifu Model (v1.2)
>pic 2 Pony Model
>twilight_sparkle, mlp, seductive
>Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 3967284458, Size: 512x512
>Not the best seed I guess

Anonymous
No.2372


>Deepfakes: Faces Created by AI Now Look More Real Than Genuine Photos
>Spoiler alert:
>The single real face in the composite image above is located in the second column from the left, fourth image from the top.
https://www.activistpost.com/2023/01/deepfakes-faces-created-by-ai-now-look-more-real-than-genuine-photos.html
>Spoiler alert:
>The single real face in the composite image above is located in the second column from the left, fourth image from the top.
https://www.activistpost.com/2023/01/deepfakes-faces-created-by-ai-now-look-more-real-than-genuine-photos.html
Anonymous
No.2389
So I tried generating something with the (((((arcane style))))) tag and got this.
Turns out if you overrate Arcane's importance you get weird satanic looking shit.
Turns out if you overrate Arcane's importance you get weird satanic looking shit.
Anonymous
No.2393


>AI images lose copyright protections
>The decision by the US Copyright Office is among the first to deal with AI-generated artwork and intellectual property
>A US federal agency has concluded that artwork made using artificial intelligence does not qualify for copyright protections, saying such images were not created by a human being and cannot be registered as legitimate IP.
>The US Copyright Office outlined its stance in a recent letter to graphic novelist Kris Kashtanova, who attempted to register a work containing images created with the help of the ‘Midjourney’ AI software. The office would only agree to copyright elements written and arranged by a human author.
https://www.rt.com/news/571952-artificial-intelligence-art-copyright/
>The decision by the US Copyright Office is among the first to deal with AI-generated artwork and intellectual property
>A US federal agency has concluded that artwork made using artificial intelligence does not qualify for copyright protections, saying such images were not created by a human being and cannot be registered as legitimate IP.
>The US Copyright Office outlined its stance in a recent letter to graphic novelist Kris Kashtanova, who attempted to register a work containing images created with the help of the ‘Midjourney’ AI software. The office would only agree to copyright elements written and arranged by a human author.
https://www.rt.com/news/571952-artificial-intelligence-art-copyright/


>>2447
This is interesting. I wonder what it means for the industry as a whole, particularly for artist who only partly use AI tools in their art process.
This is interesting. I wonder what it means for the industry as a whole, particularly for artist who only partly use AI tools in their art process.
Anonymous
No.2484
>>2481
I believe that from the very moment they use it, their human intellectual property goes in flames.
I believe that from the very moment they use it, their human intellectual property goes in flames.

Anonymous
No.2510

>Last Stand | Sci-Fi Short Film Made with Artificial Intelligence - (9:59 long)
>Disclaimed: None of it is real. It’s just a movie, made mostly with AI, which took care of writing the script, creating the concept art, generating all the voices, and participating in some creative decisions. The AI-generated voices used in this film do not reflect the opinions and thoughts of their original owners. This short film was created as a demonstration to showcase the potential of AI in filmmaking.
https://www.youtube.com/watch?v=6dtSqhYhcrs
>Disclaimed: None of it is real. It’s just a movie, made mostly with AI, which took care of writing the script, creating the concept art, generating all the voices, and participating in some creative decisions. The AI-generated voices used in this film do not reflect the opinions and thoughts of their original owners. This short film was created as a demonstration to showcase the potential of AI in filmmaking.
https://www.youtube.com/watch?v=6dtSqhYhcrs
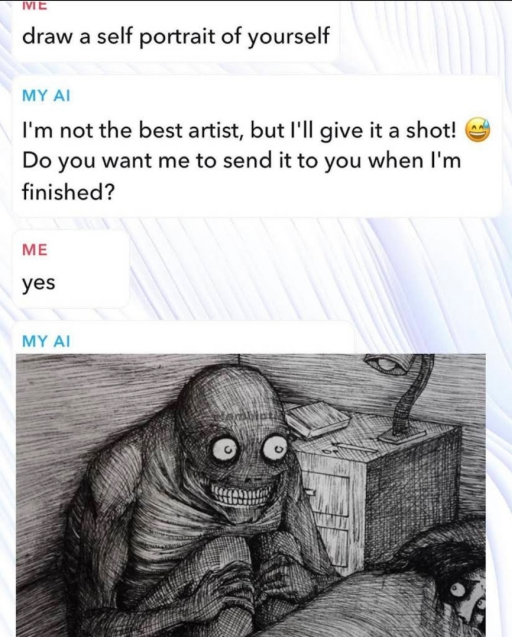






Anonymous
No.3204
1704664346.mp4 (4.1 MB, Resolution:1080x1920 Length:00:00:46, you.are.banned-20240104-0001.mp4) [play once] [loop]

Anonymous
No.3331
>Jonathan Blow on AI art and tech
https://www.youtube.com/watch?v=DP7kguY2Z6U
In a nutshell: "Mediocre artists will loose their job, and the worthy will remain".
https://www.youtube.com/watch?v=DP7kguY2Z6U
In a nutshell: "Mediocre artists will loose their job, and the worthy will remain".
366 replies and 321 files omitted.
[View All] [Last 50 Posts] [Last 200 Posts]Post pagination: [Prev] [1-100] [101-200] [201-300] [301-400] [401-466] [Next]
466 replies | 449 files | 74 UUIDs | Page 5